
El AWS Security Maturity Model tiene una recomendación en su Phase 1 — Quick Wins que parece trivial: asignar un contacto de seguridad en cada cuenta de tu AWS Organization.
No es glamorosa. No tiene un diagrama de arquitectura complejo. No requiere habilitar ningún servicio nuevo. Es literalmente completar un formulario con un nombre, un email y un teléfono.
Y sin embargo, en la mayoría de las organizaciones con las que trabajo en LATAM, no está hecha.
No porque nadie lo sepa — sino porque en entornos con decenas de cuentas, "completar un formulario" se convierte en un proceso manual que depende de que alguien se acuerde, tenga acceso, y lo haga bien en cada cuenta. Y cuando Control Tower provisiona una cuenta nueva, ese proceso empieza de cero otra vez.
La pregunta que disparó este proyecto fue simple: ¿por qué estoy haciendo esto a mano?
El problema
Una AWS Organization activa no es estática. Llegan proyectos nuevos, se crean ambientes de desarrollo, se incorporan equipos. Con Control Tower, provisionar una cuenta nueva toma minutos — y eso es exactamente lo que se quiere. El problema es lo que pasa después del provisioning.
Cada cuenta nueva nace sin contacto de seguridad. AWS usa ese contacto para enviar alertas críticas — abuse notifications, compromisos de credenciales, vulnerabilidades activas en los recursos. Si no está configurado, esas alertas van al email del root de la cuenta, que en la mayoría de los casos nadie monitorea activamente.
En una organización con 10 cuentas, se puede manejar a mano. Con 20, se empieza a omitir. Con 40, es sistemáticamente inconsistente.
El modelo de madurez es claro sobre esto: no es una recomendación avanzada. Está en Phase 1. Es baseline. Es lo que se debería tener resuelto antes de cualquier otra cosa. Y "resuelto" no significa haberlo hecho una vez en las cuentas que existen hoy — significa que cualquier cuenta que se cree mañana también lo tenga, automáticamente, sin que nadie tenga que acordarse.
Eso requiere automatización. No un runbook, no una checklist — automatización real que reaccione al evento correcto y no dependa de intervención humana.
La arquitectura
La decisión de diseño más importante de este proyecto no es la Lambda — es dónde vive y cómo se dispara.
La tentación obvia es simple: crear una regla de EventBridge en la cuenta Management que invoque la Lambda directamente. Funciona. Pero crea un acoplamiento que se lamenta después: la cuenta Management sabe que existe una Lambda, sabe dónde está, y tiene que tener permisos para invocarla cross-account. Cada nuevo consumidor de ese evento requiere tocar la cuenta Management.
La solución correcta es un Custom Event Bus en la cuenta Security.
Control Tower (Management)
→ EventBridge Rule
→ Custom Event Bus (Security)
→ EventBridge Rule
→ Lambda
→ account API (todas las cuentas)
→ Slack notification
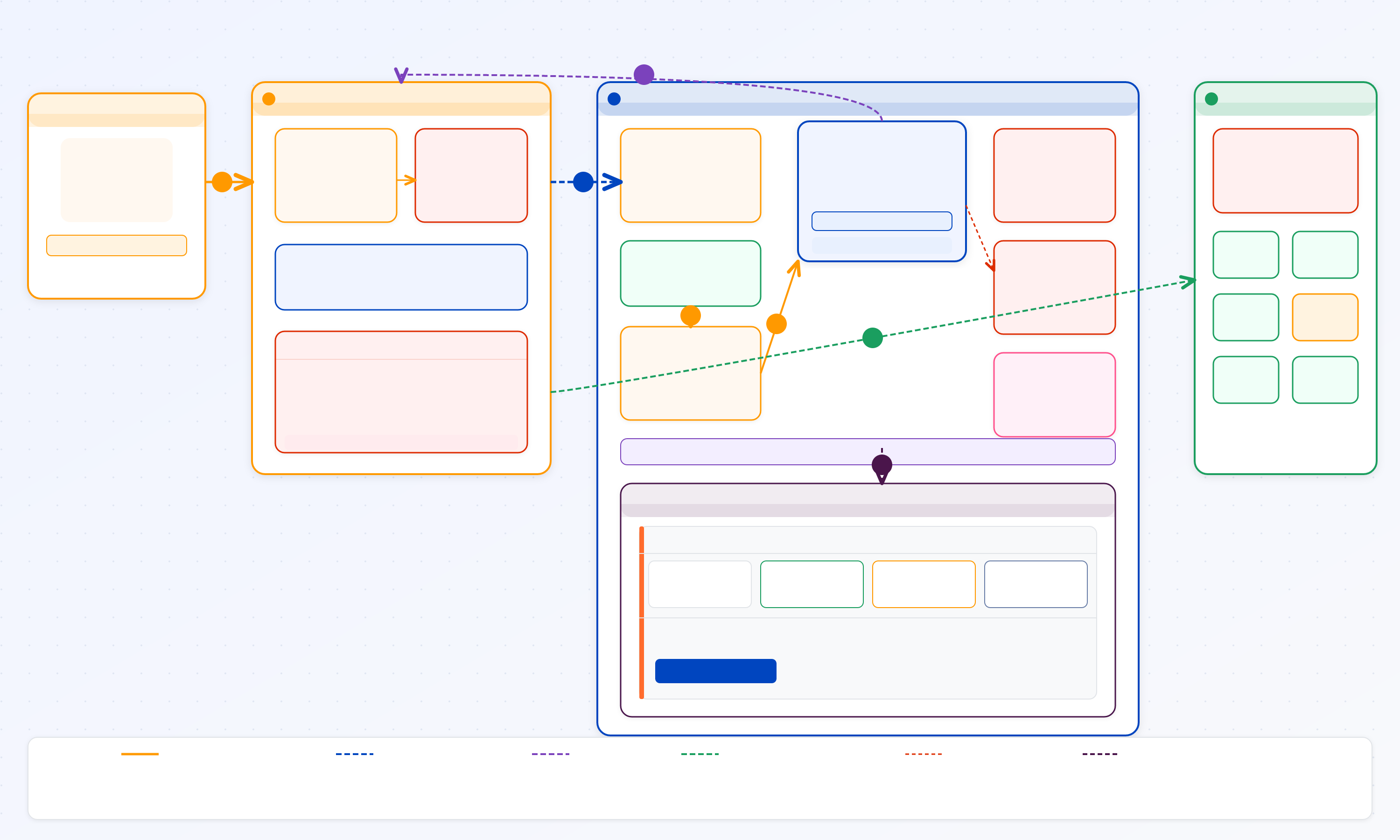
El flujo es: Management publica el evento en el Bus. Security tiene sus propias reglas que deciden qué hacer con él. Management no sabe nada de la Lambda — solo sabe que existe un Bus al que enviar eventos.
Lo que se gana con esto es extensibilidad real. El Custom Event Bus en Security se convierte en el punto central de eventos de la organización. Cuando mañana se quiere reaccionar al mismo evento de otra forma — enviar a un SIEM, disparar otra automatización, notificar a otro canal — se agrega una regla al Bus. La cuenta Management no se toca. Ese es el tipo de decisión que parece overhead al principio y que se agradece cuando el sistema crece.
CreateManagedAccount, no CreateAccount
Cuando Control Tower provisiona una cuenta, AWS emite dos eventos distintos en momentos distintos del proceso. Confundirlos es uno de los errores más fáciles de cometer — y uno de los más difíciles de diagnosticar porque ambos parecen correctos sobre el papel.
CreateAccount se emite cuando el proceso de creación comienza. En ese momento, la cuenta existe en Organizations pero Control Tower todavía no terminó de configurarla. Si se dispara la Lambda con ese evento, se intenta asignar el contacto de seguridad en una cuenta que todavía no es completamente accesible. El resultado es un error que parece un problema de permisos — y que hace perder tiempo revisando políticas IAM que están perfectamente bien.
CreateManagedAccount se emite cuando Control Tower termina el provisioning. La cuenta está lista, los roles están desplegados, se puede operar sobre ella. Este es el evento correcto.
Pero hay una segunda trampa, más sutil. El detail-type del evento no es AWS Control Tower via CloudTrail como se podría asumir — es AWS Service Event via CloudTrail. Este detalle no está bien documentado y solo se descubre de una forma: abriendo CloudTrail, encontrando el evento real que se emitió cuando CT provisionó una cuenta, y leyendo el JSON completo.
La regla de EventBridge correcta queda así:
{
"source": ["aws.controltower"],
"detail-type": ["AWS Service Event via CloudTrail"],
"detail": {
"eventName": ["CreateManagedAccount"]
}
}
Si se usa CreateAccount o el detail-type equivocado, la regla nunca dispara — o dispara en el momento incorrecto. En ambos casos, el contacto de seguridad no se asigna y no hay ningún error visible que indique por qué.
La Lambda y la idempotencia
El comportamiento más importante de esta Lambda no es lo que hace cuando encuentra una cuenta sin contacto — es lo que hace cuando encuentra una cuenta que ya lo tiene correcto.
No hace nada.
Eso parece obvio, pero tiene implicaciones de diseño concretas. La Lambda no llama a PutAlternateContact de forma ciega sobre todas las cuentas. Primero llama a GetAlternateContact, lee el valor actual, lo compara con el esperado, y solo actúa si hay una diferencia real. Si el contacto existe y está correcto, la cuenta se marca como "sin cambios" y se sigue adelante.
current = get_contact(account_id, is_management)
if current == expected:
results["unchanged"] += 1
continue
set_contact(account_id, is_management)
results["assigned"] += 1
Esto convierte a la Lambda en idempotente: se puede correr cien veces con el mismo resultado. No hay riesgo de sobreescribir un contacto que alguien actualizó manualmente en una cuenta específica — si los valores coinciden, no toca nada.
La idempotencia también resuelve el problema de las cuentas existentes. Un trigger reactivo que solo responde a CreateManagedAccount cubre las cuentas nuevas, pero no las 40 que ya existían antes de desplegar la herramienta. La solución es correr la Lambda una vez sobre toda la organización en el primer deploy — el mismo código, sin lógica adicional, porque la idempotencia garantiza que no va a romper nada que ya esté bien configurado.
El resumen de cada ejecución llega por Slack:
✅ Security Contact Enforcer
Cuentas procesadas: 40
Asignadas: 3
Actualizadas: 1
Sin cambios: 36
Ese mensaje es el que se quiere ver. Treinta y seis cuentas que ya estaban bien — y cuatro que necesitaban atención y ya no la necesitan.
La API account y sus trampas
La Lambda es simple. La API de AWS Account no lo es tanto.
Hay tres comportamientos de la API account que no están bien documentados, que no generan errores descriptivos cuando se ignoran, y que solo aparecen cuando se despliega en un entorno real.
El servicio account de AWS es una API global. Eso significa que no está disponible en todas las regiones — solo en us-east-1. Si la Lambda vive en us-east-2 o sa-east-1 y se crea el cliente boto3 sin especificar región, la llamada falla con AccessDeniedException.
El error es confuso porque parece un problema de permisos IAM. Se pueden pasar horas revisando políticas que están perfectamente bien antes de darse cuenta de que el problema es la región. La solución es explícita:
account_client = boto3.client('account', region_name='us-east-1')Una línea. Pero que solo se sabe que se necesita después de haberla necesitado.
La cuenta Management no acepta AccountIdPara las cuentas hijas, la API acepta un parámetro AccountId que indica sobre qué cuenta operar. Para la cuenta Management, ese parámetro no se puede pasar — la llamada debe hacerse sin él, en modo standalone.
Si se pasa el AccountId de la cuenta Management, la API devuelve un error. Si no hay lógica para bifurcar el comportamiento según el tipo de cuenta, la Lambda va a fallar silenciosamente en la cuenta Management o va a saltearla sin avisar.
La solución fue agregar un parámetro is_management en las funciones get_contact() y set_contact():
def get_contact(account_id, is_management=False):
if is_management:
return client.get_alternate_contact(AlternateContactType='SECURITY')
return client.get_alternate_contact(
AccountId=account_id,
AlternateContactType='SECURITY'
)
Antes de poder llamar account:GetAlternateContact o account:PutAlternateContact desde una cuenta distinta a la Management, hay que habilitar Trusted Access entre AWS Organizations y el servicio Account Management. Sin este paso, la API devuelve AccessDeniedException aunque el rol tenga todos los permisos correctos.
aws organizations enable-aws-service-access \
--service-principal account.amazonaws.com \
--profile YOUR-MANAGEMENT-PROFILE
Es un paso que se hace una sola vez y que no está en el flujo de Terraform — tiene que hacerse manualmente antes del primer deploy. Si no está documentado, es el tipo de prerequisito que hace perder horas a quien intenta reproducir el proyecto desde cero.
El Makefile como único camino
Lambda con ZIP tiene una trampa silenciosa que es fácil de ignorar hasta que cuesta tiempo real.
Cuando se actualiza el código Python en src/security_contact_enforcer.py y se construye el ZIP manualmente, Lambda sigue corriendo el código viejo. Sin ningún error. Sin ninguna advertencia. Simplemente ejecuta la versión anterior como si nada hubiera cambiado.
Lo que ocurre es que el código que Lambda ejecuta no es el archivo que se editó directamente — es el que está dentro de src/package/, el directorio que se empaqueta en el ZIP. Si se actualiza el fuente pero se olvida copiarlo al package/ antes de reempaquetar, el deploy "exitoso" de Lambda contiene código desactualizado.
En un flujo manual con varios pasos, ese olvido es inevitable. La solución es eliminar el flujo manual.
El Makefile convierte la actualización en un comando único:
update:
cp src/security_contact_enforcer.py src/package/
rm -f function.zip
cd src/package && zip -r ../../function.zip .
aws lambda update-function-code \
--function-name $(FUNCTION_NAME) \
--zip-file fileb://function.zip \
--profile $(SECURITY_PROFILE) \
--region $(AWS_REGION)
make updateEso es todo. Se edita src/security_contact_enforcer.py, se corre make update, y el ciclo completo — copiar, empaquetar, deployar — ocurre en orden sin pasos que puedan saltarse.
El Makefile no es optimización — es la única forma segura de actualizar la Lambda. Cuando hay un solo camino correcto, no hay margen para el error humano.
Cómo validarlo sin crear una cuenta
Validar que el sistema funciona end-to-end tiene dos partes independientes. Confundirlas lleva a hacer pruebas incompletas o a esperar que Control Tower provisione una cuenta real cada vez que se quiere verificar algo.
Validar la lógica de la LambdaPara esto no se necesita crear ninguna cuenta. Se elimina el contacto de seguridad de una cuenta existente manualmente:
aws account delete-alternate-contact \
--alternate-contact-type SECURITY \
--account-id YOUR-ACCOUNT-ID \
--profile YOUR-MANAGEMENT-PROFILE \
--region us-east-1
Luego se invoca la Lambda directamente:
aws lambda invoke \
--function-name security-contact-enforcer \
--payload '{}' \
--cli-binary-format raw-in-base64-out \
response.json \
--profile YOUR-SECURITY-PROFILE \
--region YOUR-REGION
cat response.json
Si el resultado muestra Asignadas: 1, Sin cambios: N-1 — la lógica completa está validada. La Lambda recorrió todas las cuentas, detectó la que estaba sin contacto, la corrigió, y dejó el resto intacto. Todo sin tocar EventBridge ni Control Tower.
Esta validación es independiente y requiere el evento real. La única forma de hacerla es crear una cuenta desde Control Tower y verificar en CloudWatch Logs que la Lambda se disparó automáticamente al recibir el evento CreateManagedAccount.
Son dos pruebas distintas que validan cosas distintas. La primera confirma que la lógica de negocio funciona. La segunda confirma que el trigger responde al evento correcto. Se necesitan ambas — pero no es necesario hacerlas juntas ni en ese orden.
El resultado
Correr la Lambda por primera vez contra una organización de 40 cuentas activas produjo esto:
✅ Security Contact Enforcer
Cuentas procesadas: 40
Asignadas: 31
Actualizadas: 4
Sin cambios: 5
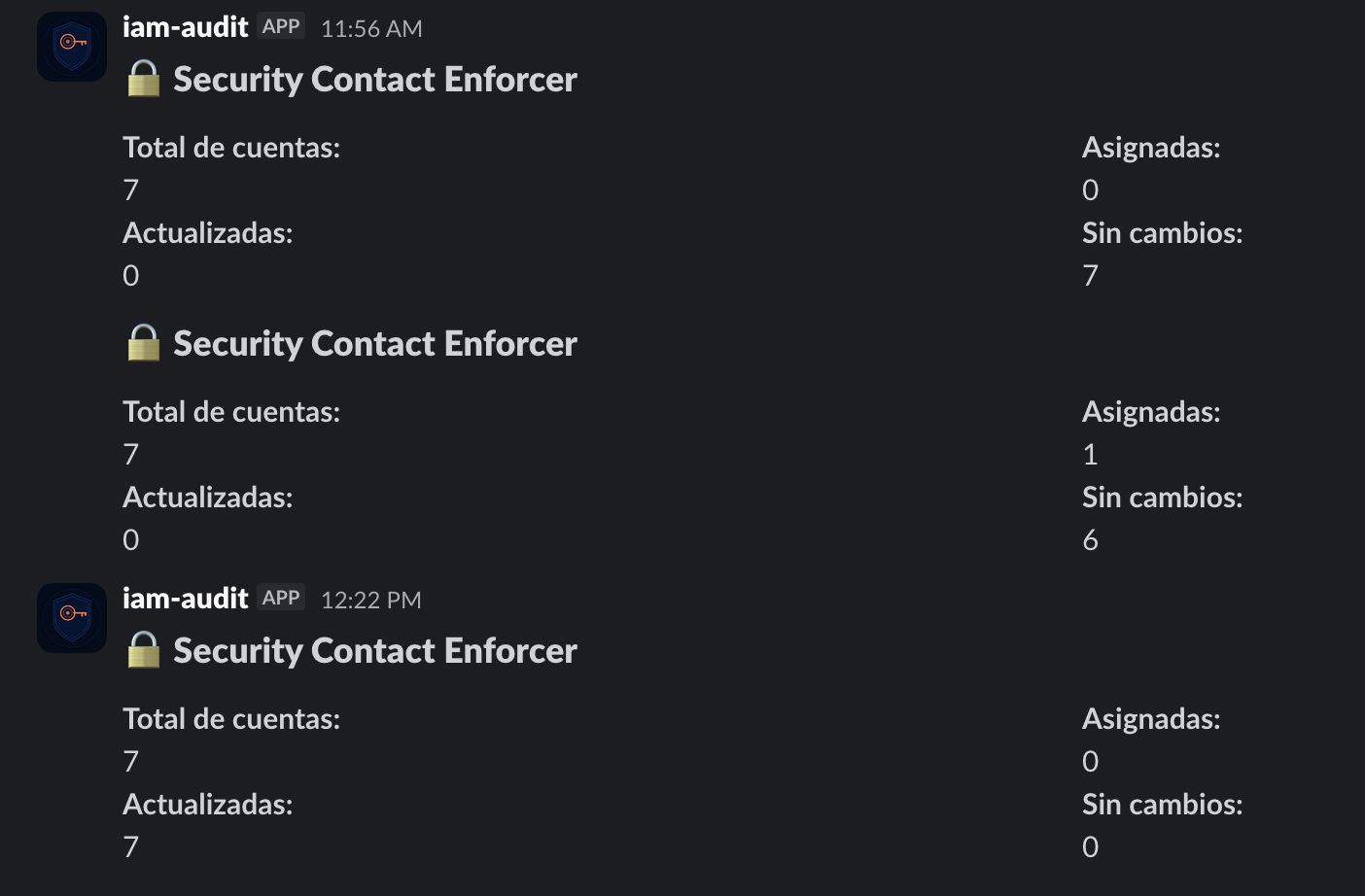
Treinta y un cuentas sin contacto de seguridad. No porque nadie se preocupara por la seguridad — sino porque nadie había construido el mecanismo para garantizarlo de forma sistemática. Las 4 actualizadas tenían un contacto configurado con datos desactualizados, de un email que ya no existía o de alguien que ya no estaba en el equipo.
Solo 5 cuentas estaban correctamente configuradas.
Ese número no es inusual. Es lo que se encuentra cuando se audita este control en organizaciones que llevan años en AWS sin automatización de baseline. El problema no es descuido — es que sin automatización, la consistencia depende de que alguien recuerde hacer algo manual en el momento correcto, cada vez que se crea una cuenta nueva.
Desde el deploy, cada cuenta que Control Tower provisiona tiene contacto de seguridad asignado antes de que el equipo que la solicitó termine de configurar sus primeros recursos. Sin tickets, sin runbooks, sin intervención humana.
El costo operacional de mantener este control ahora es cero.
El cierre
El AWS Security Maturity Model tiene decenas de controles. Algunos son complejos, costosos, y requieren semanas de planificación. Este no.
Asignar un contacto de seguridad es Phase 1 — Quick Wins. Es lo primero que se debería tener resuelto. Y sin embargo, en la práctica, es uno de los controles más frecuentemente omitidos en organizaciones multicuenta porque nadie construyó el mecanismo para garantizarlo de forma continua.
Lo que este proyecto demuestra no es que la automatización es difícil — es todo lo contrario. Una Lambda, un Custom Event Bus, Terraform y un Makefile son suficientes para convertir un proceso manual propenso a omisiones en un control que funciona solo, para siempre, sin que nadie tenga que acordarse.
Las trampas que aparecieron en el camino — el evento equivocado de Control Tower, la API global que solo vive en us-east-1, el comportamiento especial de la cuenta Management, el ZIP de Lambda que silenciosamente deployaba código viejo — no están bien documentadas en ningún lado. Aparecen cuando se despliega en producción con cuentas reales. Por eso están documentadas acá.
Si construyes seguridad en AWS en LATAM con los recursos que tienes, espero que esto te ahorre las horas que costó descubrirlo.
El repositorio está en GitHub con todo el código, el IaC en Terraform y el README completo.
🔗 GitHub: gerardokaztro/security-contact-enforcer
Sobre el autor
Gerardo Castro es AWS Security Hero y Cloud Security Engineer con foco en LATAM. Fundador y Lead Organizer del AWS Security Users Group LatAm. Cree que la mejor forma de aprender seguridad en la nube es construyendo cosas reales — no memorizando frameworks. Escribe sobre lo que construye, lo que encuentra, y lo que aprende en el camino.🔗 GitHub: gerardokaztro
🔗 LinkedIn: gerardokaztro
Comentarios