Hace unas semanas mi manager me hizo una pregunta que parecía simple:
"¿Se puede programar para que llegue solo cada semana?"El script ya recorría más de 20 cuentas AWS. Ya detectaba Access Keys de 2018 activas en producción. Ya generaba un dashboard que cualquier CISO podía leer sin abrir una hoja de cálculo. Técnicamente, el trabajo estaba hecho.
Pero "el trabajo estaba hecho" significaba que alguien tenía que acordarse de correrlo. Alguien tenía que tener Docker instalado, las credenciales configuradas, y el tiempo libre un lunes por la mañana. En un equipo de seguridad con múltiples frentes abiertos, ese "alguien" es exactamente el eslabón que falla.
La automatización no era una mejora cosmética. Era el paso que convertía una herramienta en un servicio.
La restricción que define la arquitectura
La primera decisión no fue técnica — fue de constraints.
El reporte tiene que correr una vez por semana. Tarda minutos. Cuando termina, no hay nada que mantener vivo. Pagar por infraestructura que espera 99.9% del tiempo no es solo un problema de costo — es un problema de diseño.
Con eso claro, las opciones se reducen solas.
¿Lambda? El límite de 15 minutos de ejecución es el problema. En una Organization con muchas cuentas, el script puede tardar más — y un timeout silencioso a mitad de auditoría es peor que no correr. Lambda está diseñado para workloads de milisegundos a minutos, no para procesos de auditoría que recorren decenas de cuentas en secuencia. ¿ECS Service? Un Service está diseñado para procesos que corren indefinidamente — una API, un worker que escucha una cola. Mantener un Service vivo para un job semanal es exactamente el antipatrón que queríamos evitar. Pagas por disponibilidad que nunca vas a usar. ¿EC2? Más superficie de ataque, más gestión de sistema operativo, más costo base. Descartado.La respuesta correcta es ECS Fargate Task — sin Service, sin instancias persistentes. Un Task es efímero por diseño: se levanta, ejecuta, y desaparece. No hay nada corriendo entre ejecuciones. No hay nada que parchear, monitorear, ni pagar cuando no se usa.
Eso es FinOps aplicado a seguridad: la arquitectura más barata no es la que tiene menos features — es la que no gasta en lo que no necesita.
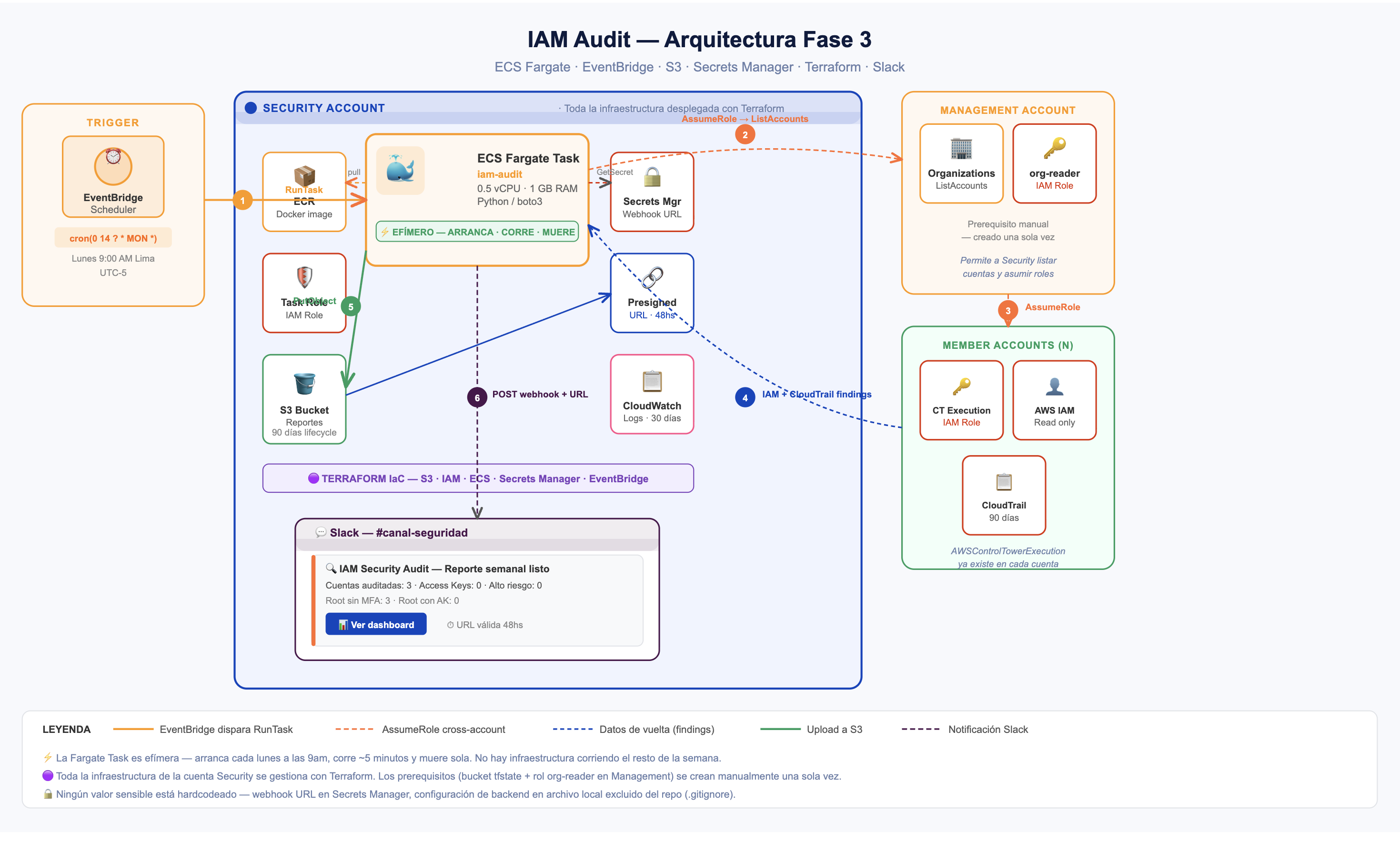
La arquitectura
El flujo completo tiene cuatro pasos y ninguna pieza innecesaria.
EventBridge Scheduler dispara un evento cada lunes a las 9am hora Lima (cron(0 14 ? MON ) — UTC-5). No hay servidor esperando, no hay proceso durmiendo. EventBridge simplemente recuerda que tiene que hacer algo, y lo hace.
Ese evento levanta un ECS Fargate Task en la cuenta Security. El task corre la imagen Docker de iam-audit — la misma que en el Part 2 corrías localmente con un comando — pero ahora en AWS, con un rol IAM asignado, sin credenciales hardcodeadas, sin intervención humana.
Cuando el task termina, sube el reporte al bucket S3 dedicado. El bucket tiene lifecycle policy de 90 días — los reportes más viejos se eliminan solos. Sin acumulación indefinida, sin costos que crecen silenciosamente.
El último paso es la notificación. El task genera un presigned URL válido por 48 horas y lo envía por Slack. Quien recibe el mensaje tiene dos días para abrir el dashboard — después el link expira. El reporte nunca sale de tu cuenta de AWS; lo que viaja por Slack es solo el acceso temporal.
EventBridge Scheduler (lunes 9am Lima)
│
▼
ECS Fargate Task
└─ imagen: gerardokaztro/iam-audit
└─ rol: iam-audit-task-role
└─ secreto: Slack webhook URL (Secrets Manager)
│
├──▶ S3 bucket (reporte + presigned URL 48hs)
│
└──▶ Slack (presigned URL)
Todo vive en la cuenta Security de la Organization. No en la cuenta de management, no en una cuenta de aplicaciones. La cuenta Security es el lugar correcto para herramientas que tocan toda la organización — aislada, con acceso controlado, auditada por separado.
Si quieres desplegarlo en otra cuenta, puedes hacerlo sin tocar nada estructural. Solo ajustas los valores de configuración — bucket name, perfil SSO, variables del entorno — y Terraform hace el resto igual.
Terraform y el partial backend
Todo el stack está definido en Terraform. Pero antes de escribir un solo recurso, hay una limitación del lenguaje que hay que entender — y que si no la conoces, te lleva directo a hardcodear cosas que no deberían estar en el código.
El bloque backend de Terraform se inicializa antes que el sistema de variables. Eso significa que esto no funciona:
terraform {
backend "s3" {
bucket = var.state_bucket # ❌ no válido
region = var.aws_region # ❌ no válido
profile = var.aws_profile # ❌ no válido
}
}
Terraform lo rechaza en el init. Las variables simplemente no existen todavía en ese momento del ciclo de vida.
La solución obvia — y la incorrecta — es hardcodear los valores directamente:
terraform {
backend "s3" {
bucket = "mi-bucket-de-state" # ❌ ahora está en el repo
region = "us-east-1"
profile = "mi-perfil-sso"
}
}
Funciona. Pero si el repo es público, acabas de exponer el nombre de tu bucket de state y tu perfil SSO. Y si el repo es privado hoy, puede no serlo mañana.
La solución correcta es el partial backend: dejas el bloque vacío en main.tf y pasas los valores en un archivo separado que va en .gitignore.
main.tf:
terraform {
backend "s3" {}
}
backend.hcl (en .gitignore, nunca en el repo):
bucket = "tu-bucket-de-state"
region = "us-east-1"
profile = "tu-perfil-sso"
Y el init queda así:
terraform init -backend-config=backend.hclEl repo incluye un backend.hcl.example con la estructura y valores de ejemplo. Quien clone el proyecto copia el archivo, llena sus valores, y corre el init. Sin fricción, sin secretos expuestos.
Esto no es un workaround — es el patrón que Terraform recomienda exactamente para este caso. La limitación del lenguaje, convertida en buena práctica de seguridad.
El Task Definition y los secrets
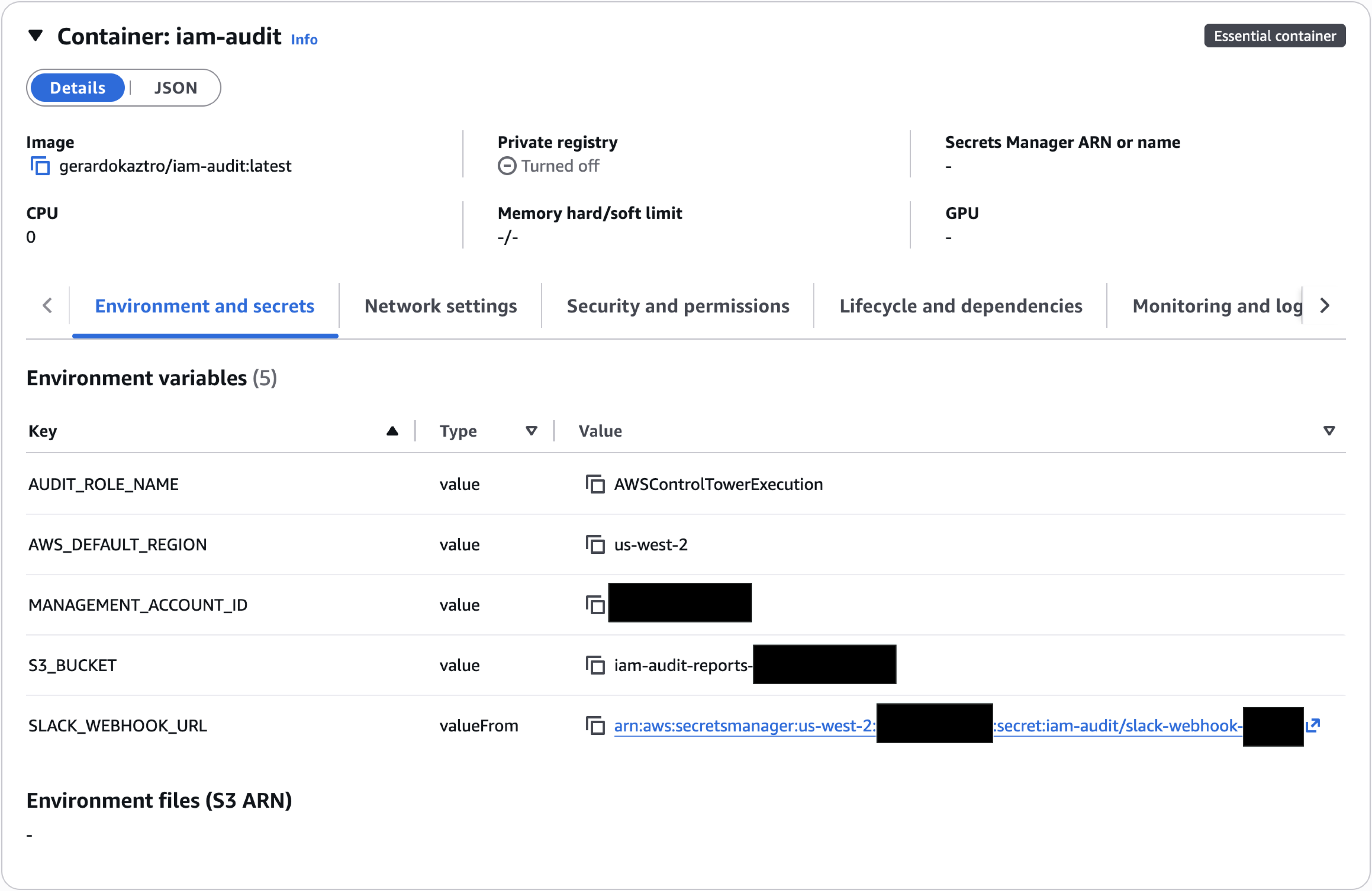
Cuando defines un ECS Task Definition en Terraform, tienes dos formas de pasarle valores al contenedor: environment y secrets. Parecen equivalentes. No lo son.
environment pasa el valor directamente como variable de entorno — visible en texto claro en la consola de ECS, en los logs del task, y en cualquier describe-task-definition que corra alguien con acceso a la cuenta.
secrets hace algo diferente: le dice al task que en el momento de ejecutarse vaya a buscar el valor a AWS Secrets Manager, lo inyecte como variable de entorno en memoria, y nunca lo escriba en ningún lado. El valor no aparece en la definición del task. No aparece en los logs. No aparece en la consola.
La Slack webhook URL es exactamente el tipo de valor que no debería estar en environment. Quien tenga esa URL puede enviar mensajes a tu canal de Slack en nombre del sistema — sin autenticación adicional, sin trazabilidad. Es una credencial, no una configuración.
En el Task Definition queda así:
secrets = [
{
name = "SLACK_WEBHOOK_URL"
valueFrom = aws_secretsmanager_secret.slack_webhook.arn
}
]
Y en Secrets Manager, el valor se crea una vez y Terraform solo referencia el ARN. El contenedor recibe la variable en runtime — el código Python la lee con os.environ["SLACK_WEBHOOK_URL"] como cualquier variable de entorno, pero nunca estuvo expuesta en ninguna definición.
El rol IAM del task
El iam-audit-task-role es el rol que asume el contenedor en runtime. Es el equivalente al perfil AWS que usabas localmente en los primeros dos posts — pero ahora es un rol con permisos definidos explícitamente en Terraform, sin credenciales de largo plazo, sin ~/.aws que montar.
Lo que necesita el task para funcionar es exactamente esto y nada más:
# Listar cuentas de la Organization
statement {
effect = "Allow"
actions = ["organizations:ListAccounts"]
resources = ["*"]
}
Asumir el rol de auditoría en cada cuenta miembro
statement {
effect = "Allow"
actions = ["sts:AssumeRole"]
resources = ["arn:aws:iam::*:role/iam-audit-role"]
}
Subir el reporte al bucket S3
statement {
effect = "Allow"
actions = ["s3:PutObject", "s3:GetObject"]
resources = ["${aws_s3_bucket.reports.arn}/*"]
}
Leer el secret de Slack
statement {
effect = "Allow"
actions = ["secretsmanager:GetSecretValue"]
resources = [aws_secretsmanager_secret.slack_webhook.arn]
}
Nada de * en resources donde no es necesario. Nada de AdministratorAccess porque "es más fácil". Cada permiso tiene una razón específica y un scope acotado.
Hay algo que vale la pena notar: este es el rol de la herramienta que audita el mínimo privilegio en toda la organización. Si ese rol tuviera permisos excesivos, estaríamos auditando un principio que no aplicamos en casa. La coherencia no es solo estética — es lo que hace que el proyecto sea creíble.
El resultado
El lunes a las 9am, sin que nadie haga nada, llega esto a Slack:
🔍 iam-audit | Reporte semanal
Organización: más de 20 cuentas auditadas
📊 Ver dashboard → https://s3.amazonaws.com/...?X-Amz-Expires=172800
⏳ Link válido por 48 horas
No hay nada que correr. No hay nada que recordar. No hay ningún engineer que tuvo que acordarse un lunes por la mañana de que existía esta herramienta.
El Fargate Task se levantó, auditó, subió el reporte, generó el presigned URL, notificó, y desapareció. El costo total de esa ejecución es de centavos — literalmente. Un task efímero que corre minutos por semana no genera una línea de costo visible en el billing mensual.
Eso es lo que significa automatizar bien: no solo que funcione solo, sino que funcione solo sin dejar rastro de infraestructura ni de costo.
Para un equipo de seguridad en LATAM que opera con presupuesto ajustado y múltiples frentes abiertos, esto no es un detalle menor. Es la diferencia entre una herramienta que se usa y una herramienta que se olvida.

El cierre
Tres posts. Tres versiones del mismo problema.
El primero era una pregunta: ¿quién tiene acceso, con qué credenciales, y desde cuándo? La respuesta fue un script Python que recorría toda la Organization en minutos y sacaba a la luz lo que nadie estaba mirando.
El segundo era una tensión: los datos estaban, pero no comunicaban para todas las audiencias. La respuesta fue un dashboard que cualquiera podía leer, detección de root account, y una imagen Docker que eliminaba la fricción de correrlo.
El tercero era una restricción operacional: alguien tenía que correrlo. La respuesta fue convertir la herramienta en un servicio — efímero, automatizado, seguro, y con un costo que no justifica una línea en el presupuesto.
Visibilidad. Comunicación. Automatización.
Eso es lo que construimos. No con plataformas comerciales, no con presupuesto de enterprise, no con un equipo de diez personas. Con Python, Docker, Terraform, y las decisiones de diseño correctas.
Si estás construyendo seguridad en AWS en LATAM con los recursos que tienes — no con los que quisieras tener — espero que esta serie te haya dado algo concreto para llevarte. No un framework para memorizar. Una herramienta que puedes correr hoy.
El repositorio está en GitHub. La imagen está en Docker Hub. El IaC está en Terraform. Todo abierto, todo documentado, todo tuyo.
⭐️ GitHub: gerardokaztro/iam-audit
🐳 Docker Hub: gerardokaztro/iam-audit
Sobre el autor
Gerardo Castro es AWS Security Hero y Cloud Security Engineer con foco en LATAM. Fundador y Lead Organizer del AWS Security Users Group LatAm. Cree que la mejor forma de aprender seguridad en la nube es construyendo cosas reales — no memorizando frameworks. Escribe sobre lo que construye, lo que encuentra, y lo que aprende en el camino.🐳 Docker Hub: gerardokaztro
⭐️ GitHub: gerardokaztro
🔗 LinkedIn: gerardokaztro
Comentarios